
RAG

RAG
池慕睡不着一、前言
首先这是作者最新的项目沉淀,作者介绍这是一套基于 Ollama DeepSeek 大模型构建的增强 RAG 知识库检索项目,在这套项目上,实现了除普通文档知识解析外,增加了 Git 代码库的拉取和解析,并提供操作接口。为工程师做项目开发时,需求分析、研发设计、辅助编码、代码评审、风险评估、上线检测等,做工程交付提效。
基于 Ollama 部署 DeepSeek 大模型,提供 API 接口。运用 Spring AI 框架承接接口实现 RAG 知识库能力。这款 RAG 知识库支持文本解析,以及 Git 代码库的解析。
工程结构采取2层架构,轻量化设计,重点在于突出 RAG 功能实现。以此方式,帮助大家更好的理解,除了工程架构外的 RAG 知识库搭建。方便大家快速上手学习。
介绍如下:
- 前端,基于 AI 工具,设计前端对话页面,完成 HTML、JS、TailwindCSS 的编码工作。
- 前端,配置跨域服务接口,前后端分离实现 UI + 服务端接口对接。
- 后端,构建双层架构,直接面向需求编码。让学习伙伴更轻松完成 RAG 知识库核心知识的学习。
- 后端,基于 Spring AI 完成 DeepSeek、OpenAI 双模型的策略对接,处理文本向量的解析和存储。
- 后端,使用 postgresql 存储切割文本向量数据,完成知识库的解析和存储。
- 后端,处理多样文本(.md、.sql、.txt、.word…)的解析储存以及Git克隆代码库遍历切割存储。
- 后端,使用 Redis 存储知识库标签,用于检索展示使用。
- 后端,基于 Flux 编写流式会话接口,以及增加知识库检索功能。
- 运维,基于 Docker 部署 Ollama 环境,完成 DeepSeek 大模型配置。
- 运维,使用 Linux、Docker、Nginx 完成项目的打包、构建、上线!
可以看到这里包含了作者针对目前一些核心的内容的分享,也是不错的,继续提高每个人的动手能力了。
根据描述推理出来的架构图如下:
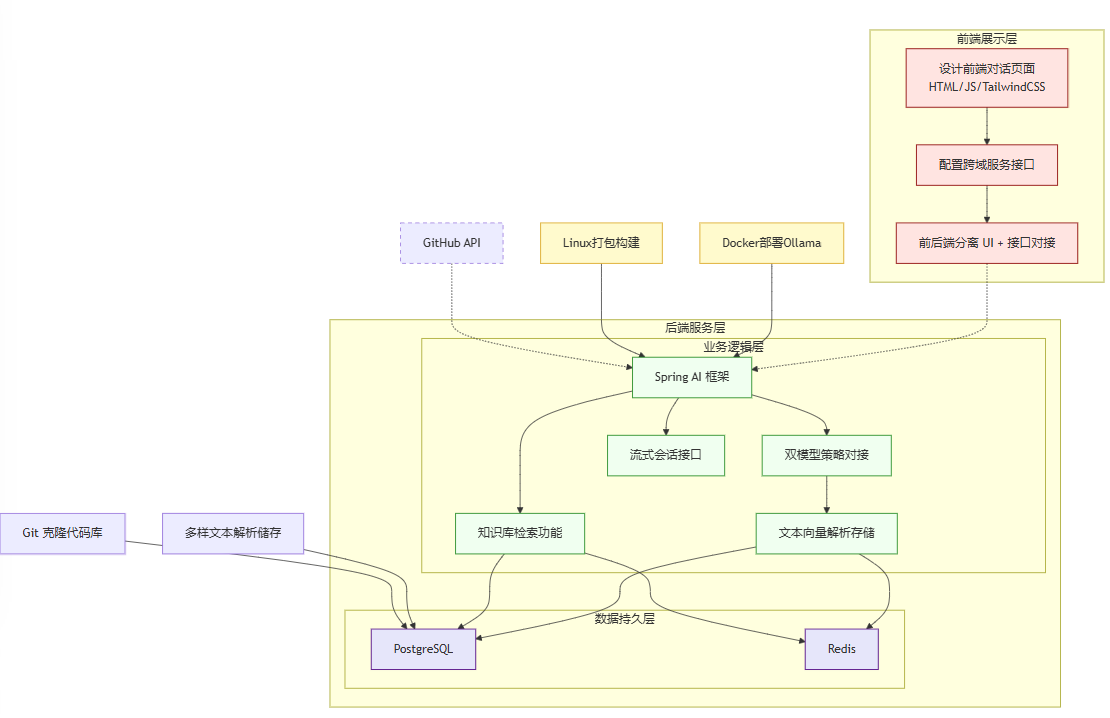
那我们分析下这里面可以学的东西:
前端技术栈
- AI工具+HTML/JS/TailwindCSS
- 技术目标:实现低代码、高响应式对话界面,降低前端开发门槛。
- 业务场景:快速构建符合大模型交互特点的UI(如连续对话、知识库检索结果显示)。
- 跨域服务接口+前后端分离
- 技术目标:解决浏览器安全策略限制,实现UI与RAG核心服务解耦。
- 业务场景:支持多端接入(Web/App/第三方系统),适应企业级系统架构。
后端技术栈
- 双层架构设计
- 技术目标:分离业务逻辑与基础设施(如向量数据库、模型API),降低学习复杂度。
- 业务场景:教学场景中聚焦RAG核心流程(检索→增强→生成),避免陷入框架细节。
- Spring AI双模型策略
- 技术目标:通过DeepSeek(国产模型)处理文本模型理解,使用OpenAI的向量模型或者4o-mini模型提高简单问题的响应速度。
- 业务场景:企业级系统需平衡成本、响应速度与生成质量。
- PostgreSQL向量存储
- 技术目标:利用pgvector扩展实现高维向量相似度检索,替代专用向量数据库降低成本。
- 业务场景:中小规模知识库(百万级文档)的高效检索。
- 多格式文本解析+Git克隆
- 技术目标:通过统一接口解析Markdown/SQL/Word等异构数据,支持代码库知识抽取。
- 业务场景:企业真实环境中的多源知识整合(如技术文档+代码+数据库)。
- Redis标签存储
- 技术目标:缓存高频检索标签,减少数据库压力。
- 业务场景:知识库运营监控(热门标签分析、检索热点追踪)。
- Flux流式会话
- 技术目标:实现类ChatGPT的逐字输出体验,降低用户等待焦虑。
- 业务场景:长文本生成场景(如报告撰写、复杂问题解答)。
运维技术栈
- Docker部署Ollama
- 技术目标:快速搭建本地大模型运行环境,规避云API的网络延迟和费用问题。
- 业务场景:离线环境部署、敏感数据本地处理。
个人建议还是使用合适的GPU云平台autodl或者高配笔记本搭建。Docker搭建资源有限制。
2.Linux/Docker/Nginx
- 技术目标:通过容器化实现开发-测试-生产环境一致性,Nginx反向代理保障高并发。
- 业务场景:企业级服务部署(负载均衡、HTTPS支持、灰度发布)。
二、正文
2.1、业务流程分析
1、首先我们来看下作者分享的业务流程图:
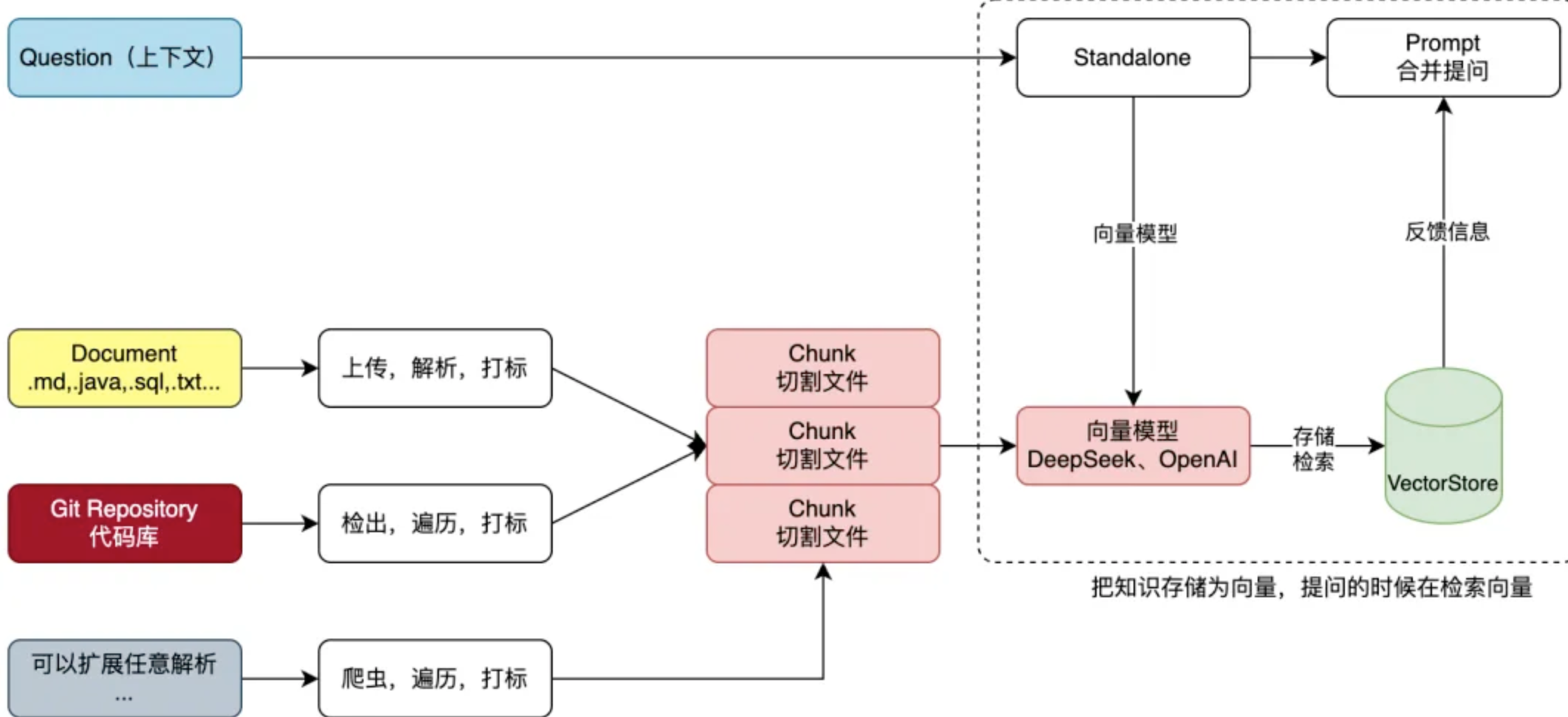
首先我们从这里可以看到两部分的任务流程:
第一部分是下发的数据准备流程,这里可以通过对各种格式的文件的解析、上传,然后分割为Chunk片段文档,也支持基于Git代码仓库的文档的处理,也支持其他第三方的文件的解析处理,然后统一封装为Chunk。然后通过向量模型结合向量数据库存储到数据库中。
第二部分就是用户提问阶段,这个时候用户会发起一个问题提问查询,然后先通过向量模型计算出来当前问题的向量,然后根据向量去数据库中查询出来相似性的片段,然后再通过提示词交给AI大模型做总结。
那么这个过程也是非常典型的RAG的过程,如下:
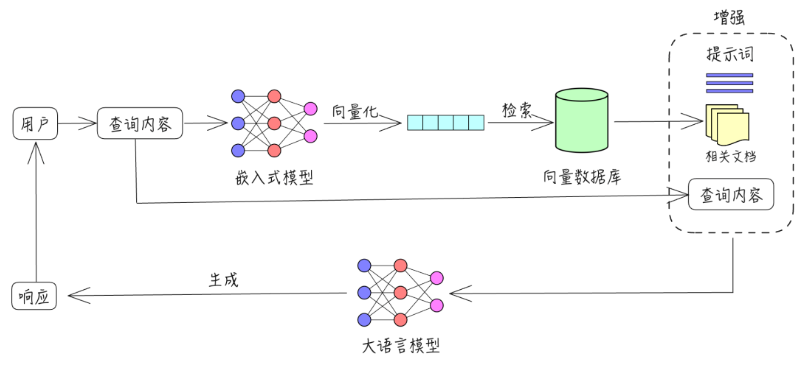
那么这里我们需要明白RAG的出现,为我们的日常业务搜索提供了新的名词与扩展:
1、相似性搜索(RAG时代的产物)
2、全文检索
3、模糊搜索
4、精确搜索
同时针对AI大模型,我们也会逐渐的发现,目前需要完成一个RAG至少需要几个不同的模型:
1、文本理解生成模型:gpt-4o、deepseek-r1
2、向量模型:text-embedding-ada-002
逐渐的会发现这里对我们的RAG技术的掌握和要求,也会逐渐的变为重要,虽然是后端开发,但是理解和掌握RAG技术也是必备的一个知识。
2.2、竞品分析
当我们做一个东西的时候,还是要参考下业界的实现,看看这个东西是否存在同类的竞品,目前对于知识库的应用常用的几个软件如下:
1、FastGPT
2、Dify
3、MaxKB
4、LangChat
那么我们为什么要自己做呢,正如作者所说:知识库都有很多现成的工具。但研发的能力不是在于功能应用,而是具备这样的开发技能储备,在有需要的时候,可以举手🙋🏻♀️”我会,我来做!“
2.3、为什么需要通过RAG技术建设知识库
之所以需要 RAG,是因为大语言模型本身存在一些局限性。
领域知识缺乏是最明显的问题。大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识。信息过时则指模型难以处理实时信息,因为训练过程耗时且成本高昂,模型一旦训练完成,就难以获取和处理新信息。此外,幻觉问题是另一个显著的局限,模型基于概率生成文本,有时会输出看似合理但实际错误的答案。最后,数据安全性在企业应用中尤为重要,如何在确保数据安全的前提下,使大模型有效利用私有数据进行推理和生成,是一个具有挑战性的问题。
由于以上的一些局限性,大模型可能会生成虚假信息。为了解决这个问题,需要给大模型外挂一个知识库,这样大模型在回答问题时便可以参考外挂知识库中的知识,也就是 RAG 要做的事情。
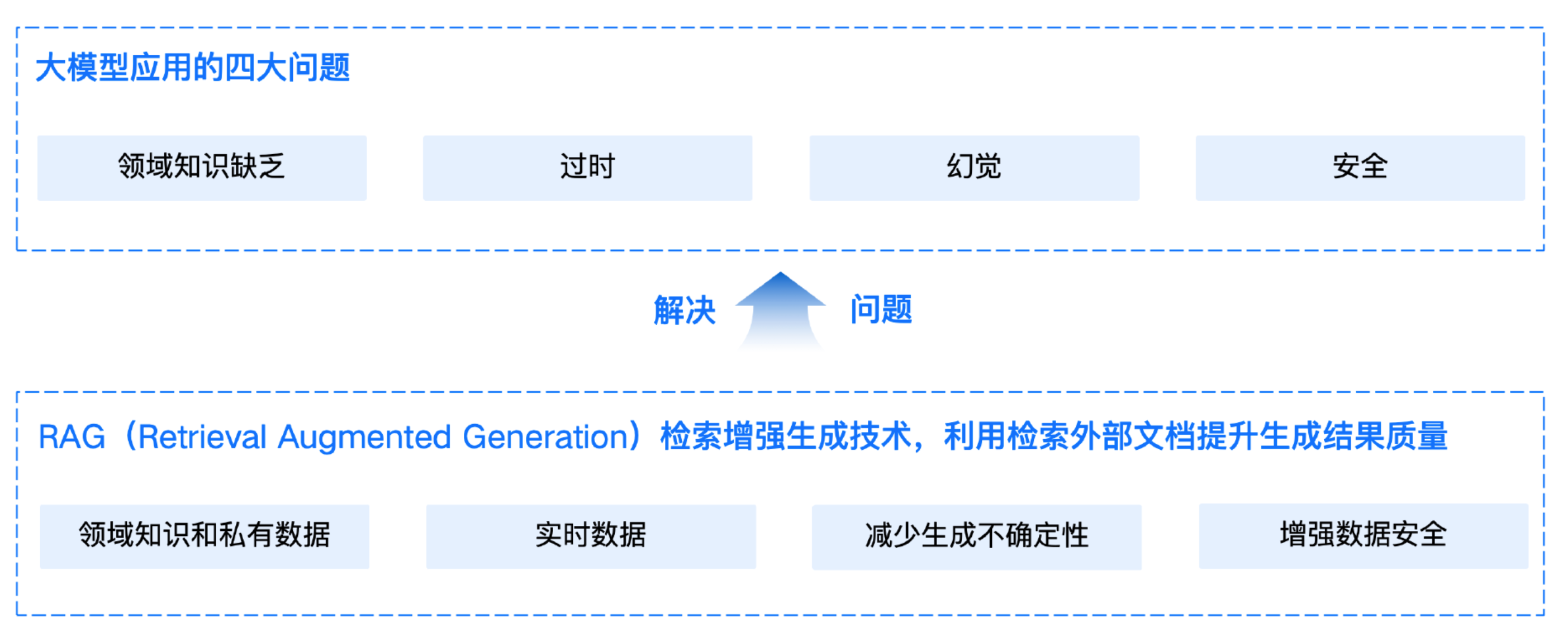
因此我们知道:RAG的目的是通过从外部知识库检索相关信息来辅助大语言模型生成更准确、更丰富的文本内容。通过将非参数化的外部知识库、文档与大模型相结合,RAG 使模型在生成内容之前,能够先检索相关信息,从而弥补模型在知识专业性和时效性上的不足,减少生成不确定性,在确保数据安全的同时,充分利用领域知识和私有数据。
2.4、向量数据库技术选型分析
可以看到作者目前选型的向量能力的库是Postgresql+pgvector,那么经过调研后,选型的原因可能如下:
| 对比维度 | ||
|---|---|---|
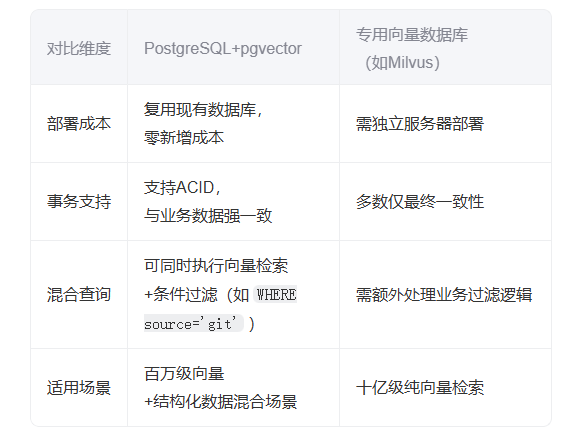
这样做的价值可能如下:
- 降本增效:中小团队无需维护Elasticsearch+Milvus等多套系统,降低运维复杂度。
- 数据闭环:知识向量与业务标签(存储在Redis)联动,实现检索结果动态加权(如优先展示最近更新的知识)
那给我们的启示是什么:
向量存储选型公式:
向量数据量 < 500万 且 需要混合查询 ➔ 选PostgreSQL
向量数据量 > 1000万 或 需要分布式扩展 ➔ 选Milvus/Pinecone
研发提效的本质:
不是替代工程师,而是通过代码知识检索(30%)+ 大模型推理(50%)+ 人工校验(20%)重构研发流程,将人力投入聚焦在高价值决策环节。
2.5、AI框架选型分析
可以看到作者选择了Spring AI,没有选择Langchain4j。目前这两个常用的Java框架都已经进入到了1.0.0的发布阶段。作者选择这个应该也是因为和Spring整合容易。Spring AI 是面向 AI 工程化的应用框架,其目标是将 Spring 生态的可移植性、模块化设计等核心原则引入 AI 领域,并通过 POJO(普通 Java 对象) 作为应用构建的基本单元。多模型供应商支持,结构化输出映射(将 AI 模型输出自动映射到 POJO)
三、总结
有了这样的分析后,我们对于作者这个项目的理解更有认识了,作者通过代码层面的RAG的知识库的实现,为开发者进行赋能、提效。
期待作者带领我们实现有一个AI领域的动手能力极大提高的内容:
那接下来这个东西对于我们的研发价值是什么了?
全流程研发提效引擎
- 场景案例:当工程师需要分析新需求时,系统自动检索相似历史项目的代码设计(如Git库中SpringBoot+vue.js的订单系统),生成模块划分建议(Controller层接口设计/Service层逻辑拆解),效率提升50%+。
- 关键能力:通过代码库语义检索(而非单纯字符串匹配),快速定位关联代码片段。





